
EveryLinguaAI — Multilingual Voice Assistant
Designed and developed a production-style AI voice assistant system capable of real-time multilingual interaction, combining speech recognition, language translation, and conversational AI into a cohesive, extensible architecture.
- Role
- AI / Backend Developer
- Timeline
- 2025 - 2026
- Stack
- Python, OpenAI GPT APIs, SpeechRecognition, PyAudio
The Problem
Most voice assistants are limited in multilingual support and struggle to provide seamless, context-aware interactions across diverse languages. Additionally, many lack flexibility in configuration, making them difficult to adapt to real-world environments and different hardware setups.
Architecture
Built as a modular, event-driven voice system with dedicated components for wake-word detection, speech processing, AI interaction, and audio output, enabling scalability and maintainability.
Implementation
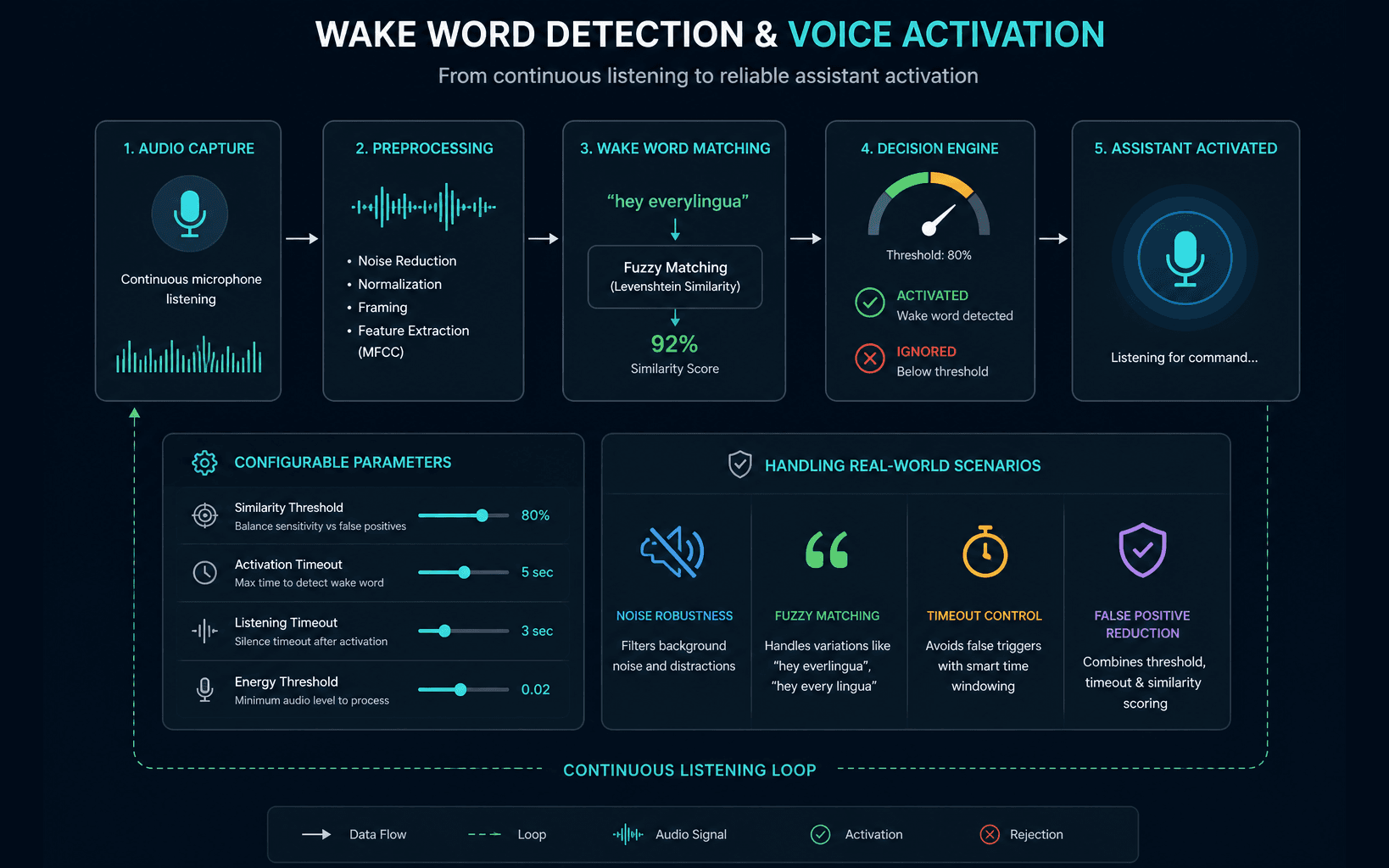
Wake Word Detection & Voice Activation
Implemented a wake-word system with fuzzy matching to reliably activate the assistant in real-world conditions. Designed configurable thresholds and timeout handling to balance responsiveness and false positives.
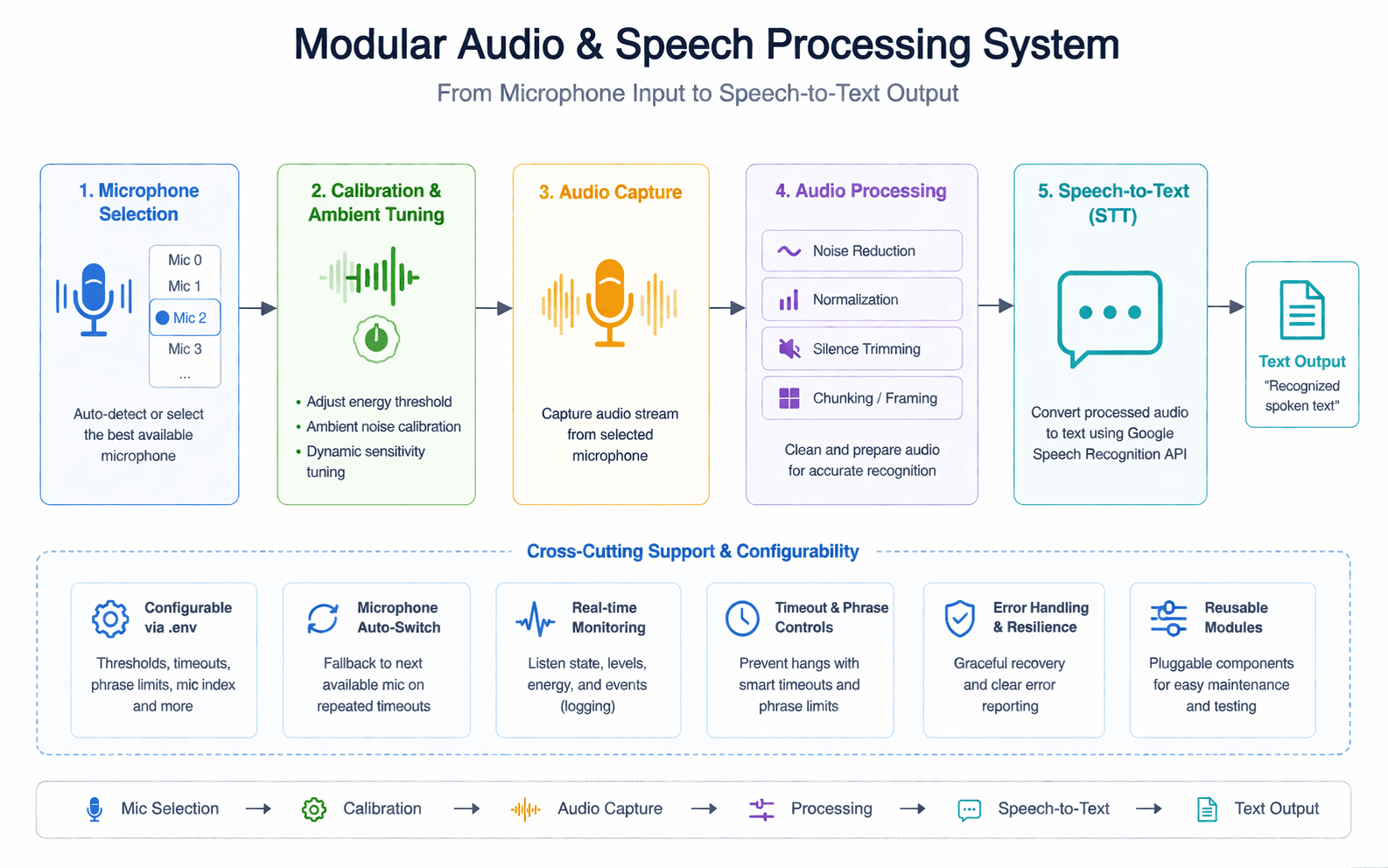
Modular Audio & Speech Processing System
Developed a structured audio pipeline handling microphone selection, calibration, and speech-to-text conversion. Built reusable modules for capturing, processing, and normalizing audio input across multiple environments.
from deep_translator import GoogleTranslator
from openai import OpenAI
client = OpenAI()
def generate_response(user_input, source_lang="auto", target_lang="en"):
translated_input = GoogleTranslator(source=source_lang, target="en").translate(user_input)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": translated_input}],
max_tokens=120
)
output_text = response.choices[0].message.content
return GoogleTranslator(source="en", target=target_lang).translate(output_text)Multilingual AI Conversation Engine
Integrated OpenAI GPT models with dynamic language detection and translation to enable context-aware conversations across 50+ languages. Built a processing pipeline that translates user input into a common language (English) for consistent AI reasoning, then converts responses back into the user’s preferred language. Implemented flexible prompt structures and token limits to balance response quality and cost efficiency, while maintaining low latency for real-time interaction. Designed the system to be easily extendable for additional languages, translation providers, and conversational behaviors.
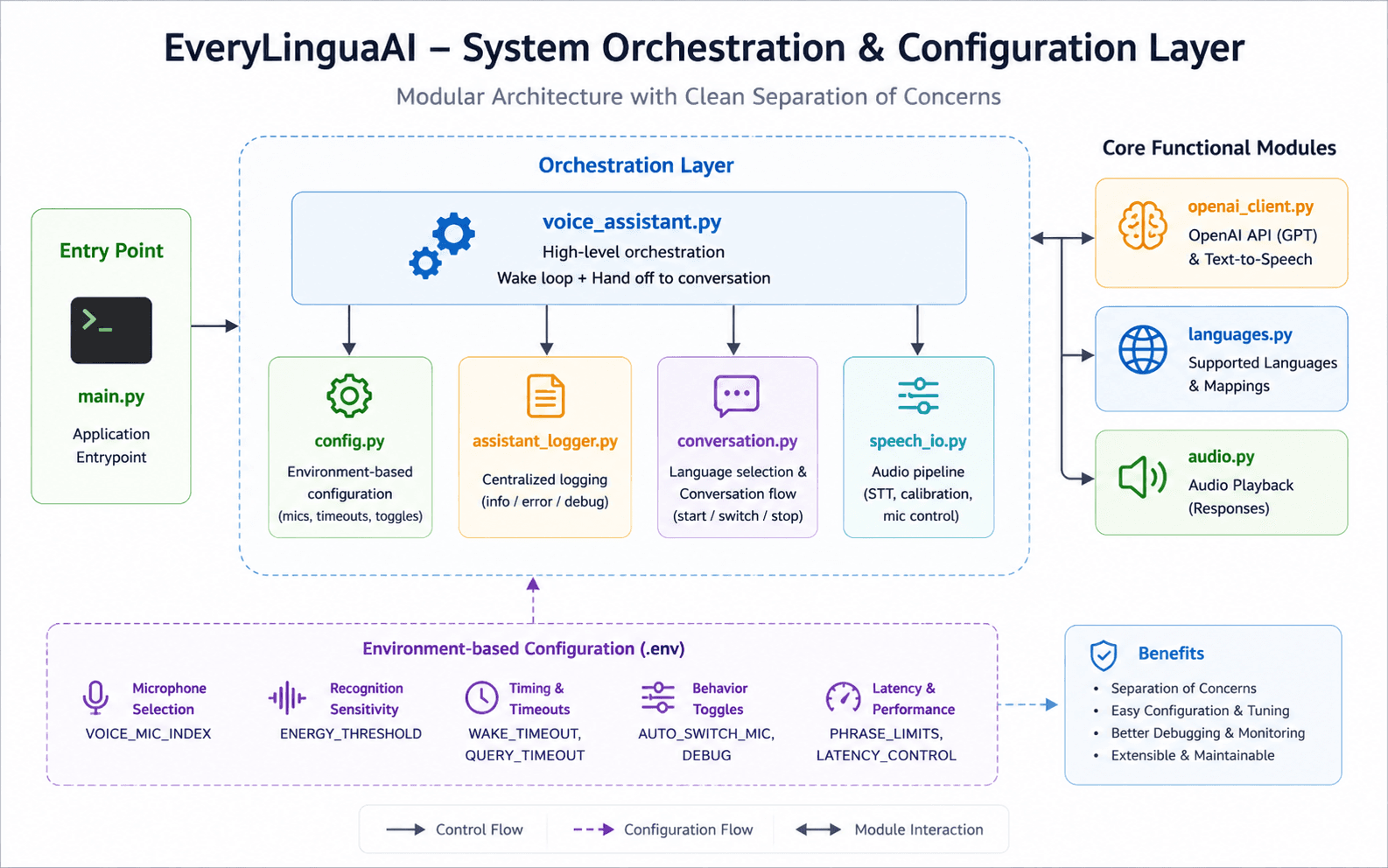
System Orchestration & Configuration Layer
Architected a clean separation of concerns with modules for orchestration, configuration, logging, and conversation flow. Enabled environment-based configuration for microphone tuning, latency control, and debugging.
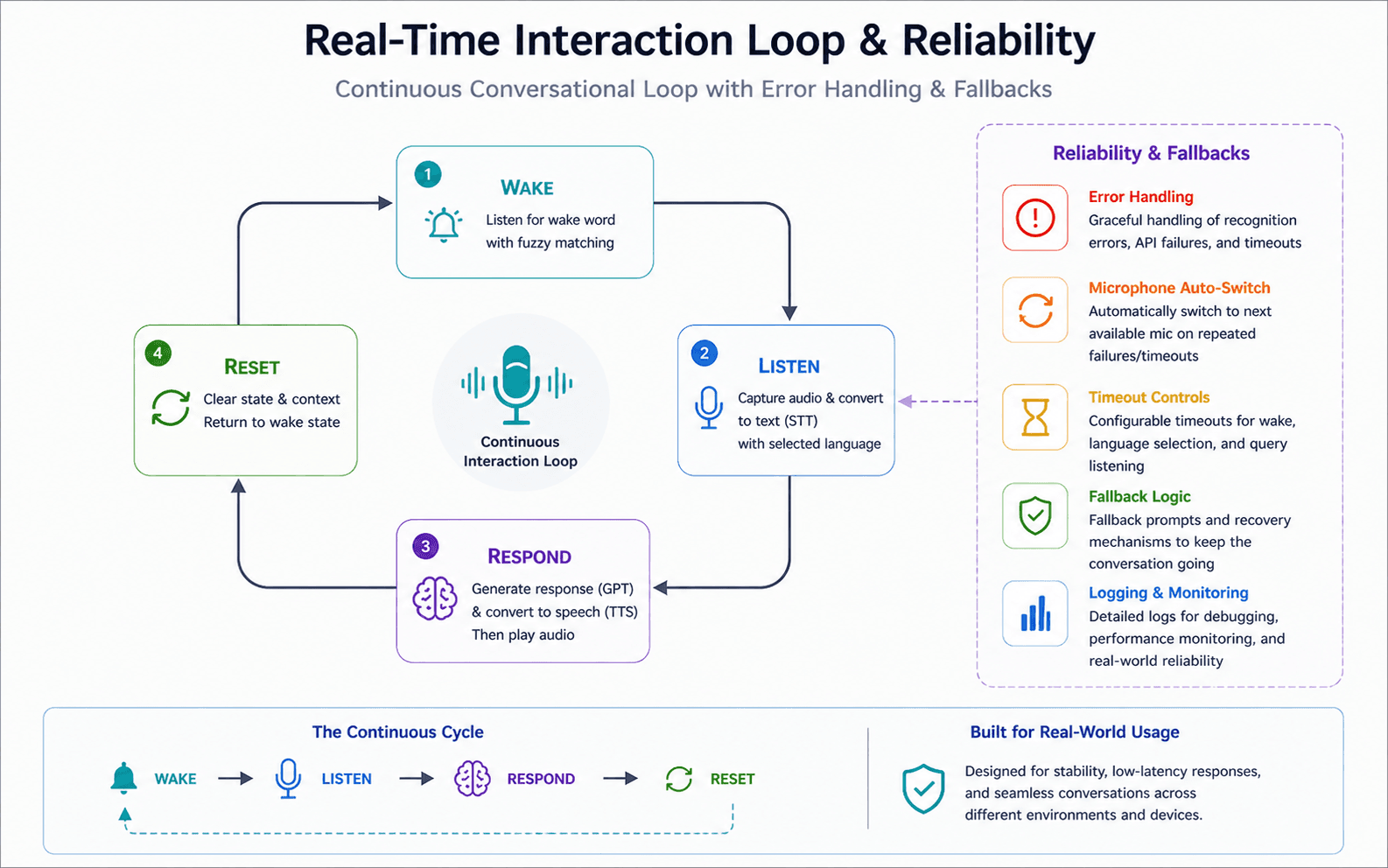
Real-Time Interaction Loop & Reliability
Built a continuous interaction loop supporting wake, listen, respond, and reset cycles. Implemented error handling, fallback logic, and microphone auto-switching to ensure stability in real-world usage.
Results
Lessons & Growth
This project helped me grow from building standard backend systems to designing real-time, AI-driven applications that interact directly with users. I gained hands-on experience working with audio processing, speech recognition, and multilingual pipelines, while learning how to structure a system that balances low latency with reliable performance. Building a continuous interaction loop pushed me to think carefully about error handling, state management, and user experience in real-world conditions. It also strengthened my understanding of modular architecture, where separating audio, AI, and orchestration layers made the system easier to scale and extend. Overall, it deepened my ability to design intelligent, interactive systems that combine AI with real-time input/output processing in a practical and production-focused way.